Comparison of 2 search algorithms for Symbiostock
|
A powerful feature of Symbiostock is the ability to find related images. The first implementation used a straightforward algorithm - assign 1 point for every time
two images shared a keyword tag. This works remarkably well, but there are
occasional oddities, both false positives and false negatives.
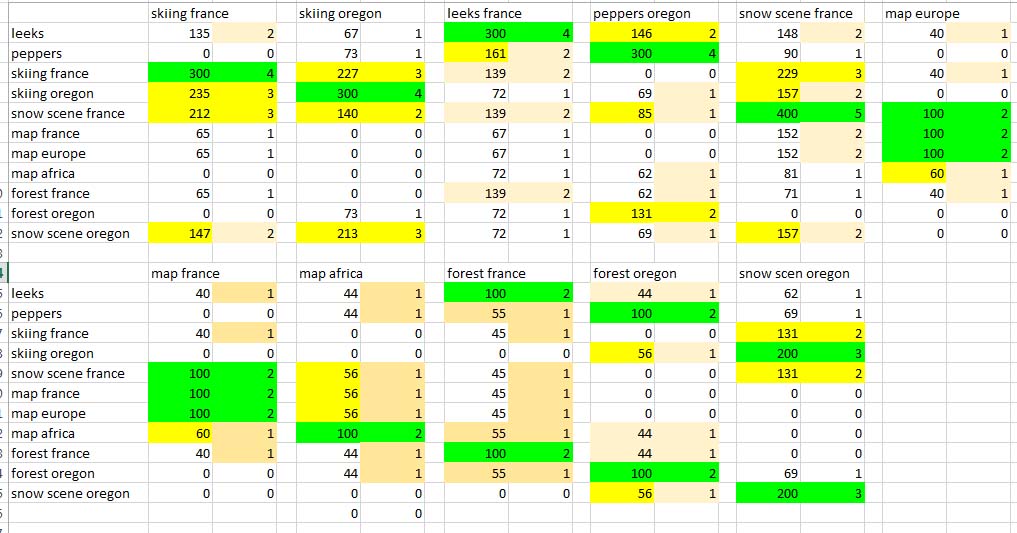
A second algorithm developed from the observation that commonly used keywords may have an influence that outweighs their utility. For example common keywords like 'Seattle' or 'blue' are less useful in matching than uncommon ones like 'skier' or 'map', so a better result would be to weight the matches, giving less relevance to common keyword. I set up a toy matrix with 11 images and 9 keywords.
| ||||
Then I applied the 2 algorithms producing a series of tables:
The left hand columns show the weighted search results. Results are normalized, re-calculated so they total 100. For example, when an image uses keywords 'France', occurring 6 times in the database, and 'map' used only 4 times, the normalized values would be 40 for 'France' and 60 for 'map'. To get a score, just add the normalized values for each keyword. So, in the table for 'map France' we get a top score of 100 for 'snow scene France, 'map France' and 'map Europe'. The 3rd choice is 'map Africa'. Note that the single value algorithm finds the first 2 matches, but then has 4 other matches with no way to distinguish among them. Note also, that the weighted algorithm can make finer distinctions - eg with the image ' skiing in France' , the weighted approach favors "skiing Oregon' slightly over 'snow scene France' and by a larger factor over 'snow scene Oregon' . Results: even with this simplified toy model, the results are conclusive -- in every case, the weighted model produces a better set of similar images, usually with little or no ambiguity. With more keywords and more images, the accuracy should improve. |
|
|